Level 2: The Integrator (GovOps & Visibility)
Goal: Transform MLOps artifacts into Regulatory Evidence with a GovOps layer.
Prerequisite: Level 1 (The Engineer)
Context: Continuing with “The Project” (Loan Credit Scoring).
1. The Bottleneck: “It works on my machine”
Section titled “1. The Bottleneck: “It works on my machine””In Level 1, you fixed the bias locally. But your manager denies it because they can’t see the proof. Emails with screenshots are not compliance.
2. The Solution: The GovOps Layer
Section titled “2. The Solution: The GovOps Layer”In GovOps (Assurance over MLOps), we don’t treat compliance as a separate manual step. Instead, we use your existing MLOps infrastructure (MLflow, WandB) as an Evidence Buffer that automatically harvests the proof of safety during the training process.
A. The Integration (Implicit Assurance)
Section titled “A. The Integration (Implicit Assurance)”In a professional pipeline, assurance is a layer that wraps your training. Every time you train a model, you verify its compliance.
Your experiment tracker now tracks two types of performance: Accuracy (Operational) and Compliance (Regulatory).
import mlflowimport venturalitica as vlfrom dataclasses import asdictfrom ucimlrepo import fetch_ucirepofrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegression
mlflow.set_tracking_uri("sqlite:///mlflow.db")mlflow.set_experiment("loan-credit-scoring")
# 0. Load the UCI German Credit dataset (ID: 144)dataset = fetch_ucirepo(id=144)df = dataset.data.features.copy()df["class"] = dataset.data.targets
X = df.select_dtypes(include=['number']).drop(columns=['class'])y = df['class']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. Start the GovOps Session (Implicitly captures 'Audit Trace')with mlflow.start_run(), vl.monitor("train_v1"): # 2. Pre-training Data Audit (Article 10) vl.enforce( data=df, target="class", gender="Attribute9", age="Attribute13", policy="data_policy.oscal.yaml" )
# 3. Train your model model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train)
# 4. Post-training Model Audit (Article 15: Human Oversight) # Download model_policy.oscal.yaml: # https://github.com/venturalitica/venturalitica-sdk-samples/blob/main/scenarios/loan-credit-scoring/policies/loan/model_policy.oscal.yaml test_df = X_test.copy() test_df["class"] = y_test test_df["prediction"] = model.predict(X_test) test_df["Attribute9"] = df.loc[X_test.index, "Attribute9"].values
results = vl.enforce( data=test_df, target="class", prediction="prediction", gender="Attribute9", policy="model_policy.oscal.yaml" )
# 5. Log everything to the Evidence Buffer passed = all(r.passed for r in results) mlflow.log_metric("val_accuracy", model.score(X_test, y_test)) mlflow.log_metric("compliance_score", 1.0 if passed else 0.0) mlflow.log_dict([asdict(r) for r in results], "compliance_results.json")
if not passed: # CRITICAL: Block the pipeline if the model is unethical raise ValueError("Model failed ISO 42001 compliance check. See audit trace.")import wandbimport venturalitica as vlfrom dataclasses import asdictfrom ucimlrepo import fetch_ucirepofrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegression
wandb.init(project="loan-credit-scoring")
# 0. Load the UCI German Credit dataset (ID: 144)dataset = fetch_ucirepo(id=144)df = dataset.data.features.copy()df["class"] = dataset.data.targets
X = df.select_dtypes(include=['number']).drop(columns=['class'])y = df['class']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 1. Open a Monitor Contextwith vl.monitor("wandb_sync"): # 2. Pre-training Data Audit (Article 10) vl.enforce( data=df, target="class", gender="Attribute9", age="Attribute13", policy="data_policy.oscal.yaml" )
# 3. Train your model model = LogisticRegression(max_iter=1000) model.fit(X_train, y_train)
# 4. Post-training Model Audit (Article 15) # Download model_policy.oscal.yaml: # https://github.com/venturalitica/venturalitica-sdk-samples/blob/main/scenarios/loan-credit-scoring/policies/loan/model_policy.oscal.yaml test_df = X_test.copy() test_df["class"] = y_test test_df["prediction"] = model.predict(X_test) test_df["Attribute9"] = df.loc[X_test.index, "Attribute9"].values
audit = vl.enforce( data=test_df, target="class", prediction="prediction", gender="Attribute9", policy="model_policy.oscal.yaml" )
# 5. Log Compliance Artifactsartifact = wandb.Artifact('compliance-bundle', type='evidence')artifact.add_file(".venturalitica/results.json")artifact.add_file(".venturalitica/trace_wandb_sync.json")wandb.log_artifact(artifact)
passed = all(r.passed for r in audit)wandb.log({"accuracy": model.score(X_test, y_test), "compliance": 1.0 if passed else 0.0})
if not passed: raise ValueError("Model rejected by GovOps policy.")B. The Verification (Dashboard)
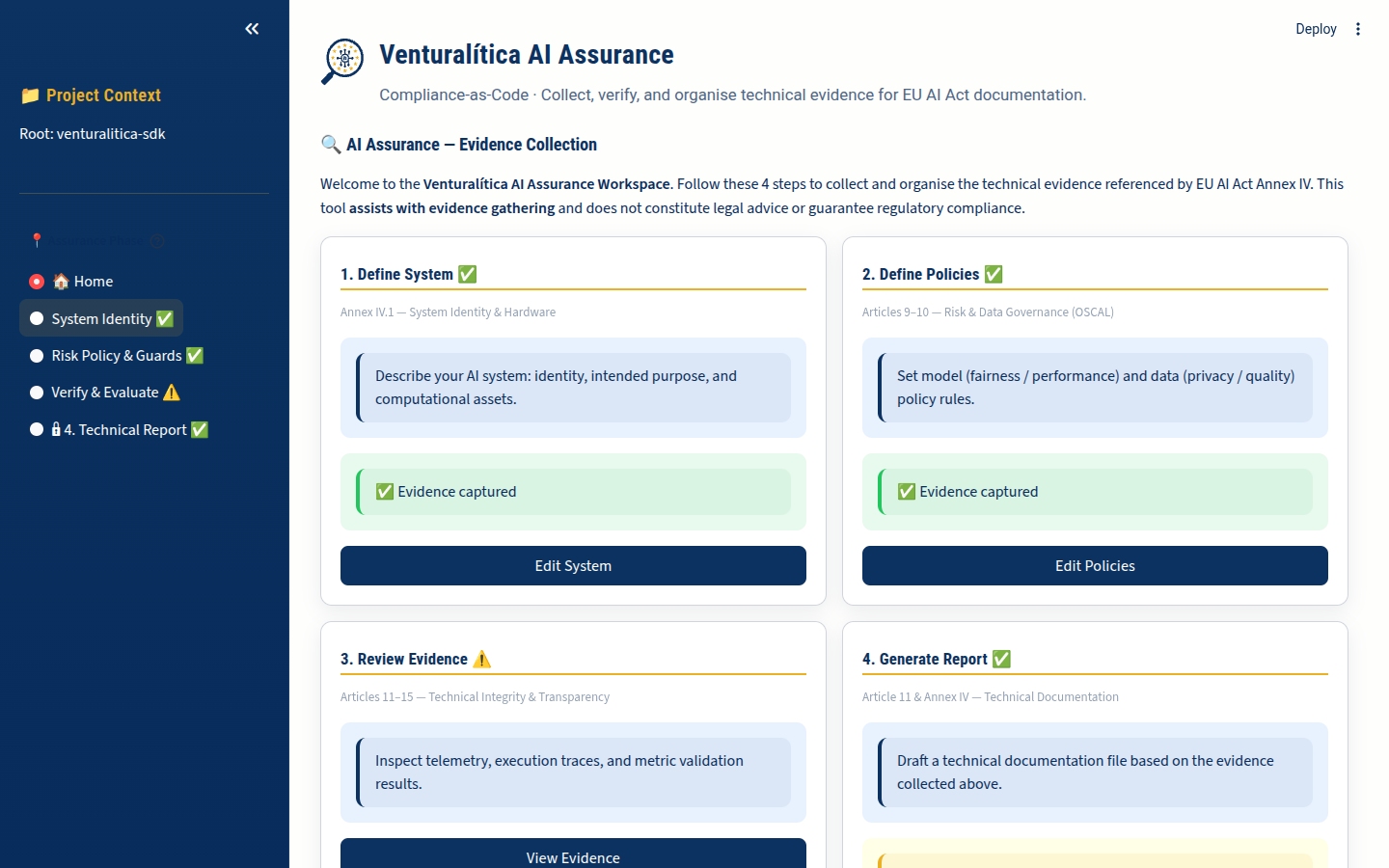
Section titled “B. The Verification (Dashboard)”Now that the code has run, let’s verify what we shipped.
- Run the UI:
Terminal window venturalitica ui - Log Check: Verify that
.venturalitica/results.jsonexists (this is the default output ofenforce). - Navigate to “Policy Status”: Confirm your “Risk Treatment” (the adjusted threshold) is recorded.
Key Insight: “The report looks professional, and I didn’t write a single word of it.”
3. Deep Dive: The Two-Policy Handshake (Art 10 vs 15)
Section titled “3. Deep Dive: The Two-Policy Handshake (Art 10 vs 15)”Professional GovOps requires a separation of concerns. You are now managing two distinct assurance layers:
- Level 1 (Article 10): Checked the Raw Data against
data_policy.yaml. The goal was to prove the dataset itself was fair before wasting energy on training. - Level 2 (Article 15): Checks the Model Behavior against
model_policy.yaml. The goal is to prove the AI makes fair decisions in a “Glass Box” execution.
| Stage | Variable Mapping | Policy File | Mandatory Requirement |
|---|---|---|---|
| Data Audit | target="class" | data_policy.oscal.yaml | Article 10 (Data Assurance) |
| Model Audit | target="class", prediction="prediction" | model_policy.oscal.yaml | Article 15 (Human Oversight) |
This decoupling is the core of the Handshake. Even if the Law (> 0.5) stays the same, the subject of the law changes from Data to Math.
4. The Gate (CI/CD)
Section titled “4. The Gate (CI/CD)”If compliance_score == 0, the build fails.
GitLab CI / GitHub Actions can now block a deployment based on ethics, just like they block on syntax errors.
5. Take Home Messages
Section titled “5. Take Home Messages”- GovOps is Native: Assurance isn’t an extra step; it’s a context manager (
vl.monitor) around your training. - Telemetry is Evidence: RAM, CO2, and Trace results are not just for metrics — they fulfill Article 15 oversight.
- Unified Trace:
vl.monitor()captures everything from hardware usage to AST code analysis in a single.jsonfile. - Zero Friction: The Data Scientist continues to use MLflow/WandB, while the SDK harvests the evidence.
References
Section titled “References”- API Reference —
enforce()andmonitor()signatures - Policy Authoring — How to write OSCAL policies
- Probes Reference — What
monitor()captures automatically - Column Binding — How
gender="Attribute9"works